Eine kurzer Überblick zu den inhaltlichen & technologischen Grundlagen von SAP HANA und SAP Fiori.
SAP S/4HANA
Die Software-Suite S/4HANA (vorgestellt 2015) ist der Nachfolger von SAP R/3. Das "S" in SAP S/4HANA steht für das Prinzip „Simple“ und die Zahl "4" für die 4. Produktgeneration. Das Produkt (mit den Modulen / Komponenten für ERP, CRM, SRM, etc.) fußt auf der In-Memory und Spalten-orientierten Datenbank SAP HANA und bietet eine neue, HTML5 basierte Benutzeroberfläche, gemäß dem SAP-Fiori Standard.
Die SAP hat ihre verschiedenen fachlichen Module nicht einfach technisch portiert, sondern Optimierungen der Benutzeroberfläche, des ABAP Codes sowie insbesondere im Datenmodell vorgenommen. So gibt es, als nur ein Beispiel von vielen, im Modul SAP-FI eine neue Tabelle „Integrierter Buchungsbeleg“ (Universal Journal) der Finanzdaten mit Daten aus dem Controlling verknüpft.
SAP S/4HANA wird von Branchenkennern als die bedeutendste Innovation seit über zwei Jahrzehnten und die tiefgreifendste Adaption der SAP ERP -und Plattform Strategie betrachtet.
Eine Umstellung von SAP/R3 auf S/4HANA ist in vielen Fällen ähnlich komplex, wie die Umstellung von SAP/R2 auf SAP/R3 (veröffentlicht 1995).
Die SAP SE hat bereits angekündigt, dass der Support für SAP/R3 (und damit auch für den heutigen SAP GUI) im Jahre 2025 auslaufen wird. Wohlgemerkt, der Support, also die Wartung. Es ist davon auszugehen, dass ab 2018 alle wesentlichen Weiter –und Neuentwicklungen nur noch auf der neuen Plattform S/4HANA stattfinden.
SAP Fiori UX
SAP Fiori ist der Oberbegriff für die neuen SAP UX (= User Experience) Guidelines (Richtlinien) und das Herzstück der zukünftigen SAP-UI-Strategie.
Die technische Implementierung des Design-Leitfadens Fiori nennt sich SAPUI5, ein etwa 15MB schweres MV* Framework, das auf jQuery basiert (ähnlich dem von Google entwickelten AngularJS).
SAPUI5 basiert auf HTML5 (und CSS3), also einer Spezifikation die seit 2014 bei Browser-basierten Applikationen Standard ist.
SAP HANA Architektur
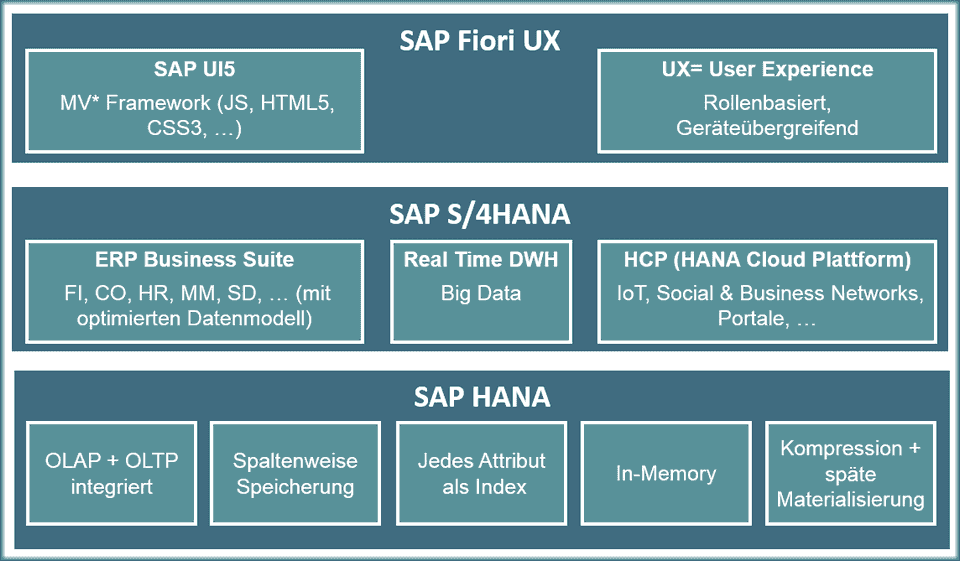
Die Übersicht zeigt die Architektur:
Zunächst die SAP Fiori basierte Präsentationsschicht, dann S/4HANA mit den ERP Applikationen und dem Reporting (DWH) und zum Schluss die SAP HANA spaltenbasierte, in-Memory basierte Datenbank.
SAP HANA Datenbank
SAP HANA ist eine technologische Architektur, die von der SAP SE entwickelt und vermarktet wird. Im Kern besteht sie aus einer in-Memory, spaltenorientierten, relationalen Datenbank.
Entwicklung
Die Entwicklung von SAP HANA startete mit dem Ziel, eine Datenbank für die Echtzeit-Analyse großer Datenmengen zu entwickeln (typische Big Data Anwendungsfälle). In der frühen Phase wurden verschiedene Technologien von der SAP SE entwickelt oder erworben.
- Die TREX (Text Retrieval and information EXtraction) Suchmaschine (speicherinterne und spaltenorientierte Suchmaschine) und seit 2005 Bestandteil der SAP BI (NetWeaver) Komponente.
- P * TIME (In-Memory-OLTP-Plattform von SAP im Jahr 2005 erworben).
- MaxDB mit seiner In-Memory-LiveCache-Engine.
Die erste Demonstration der Plattform fand 2008 statt: Teams der SAP SE, des Hasso-Plattner-Instituts und der Stanford University demonstrierten eine Anwendungsarchitektur für Echtzeitanalysen und Aggregation. Vishal Sikka, ehemaliger Vorstandsvorsitzender der SAP SE, erwähnte diese Architektur als "Hassos neue Architektur". Daraus stabilisierte sich irgendwie der Name HANA, zwischenzeitlich auch „High-Performance Analytic Appliance“ genannt, heute aber zumindest ohne offizielle Bedeutung, also kein Akronym! SAP HANA war viele Jahre ausschließlich für DWH Systeme konzipiert und verfügbar.
- Die erste HANA Auslieferung erfolgte Ende 2010 und zwar als eine Appliance, da SAP HANA nur auf speziellen SUN Servern lief.
- Ende 2012 kündigte SAP eine Plattform als Service-Angebot namens SAP HANA Cloud Plattform an.
- Mitte 2013 wurde die SAP Business Suite (also erstmalig klassische ERP Komponenten) auf SAP HANA verfügbar.
- Im November 2016 wurde SAP HANA 2 angekündigt, das Erweiterungen für mehrere Bereiche wie Datenbankverwaltung und Anwendungsverwaltung bietet und zwei neue Cloud-Services umfasst: Textanalyse und Geoanalyse.
- Seit März 2017 ist SAP HANA in einer Express-Edition verfügbar; eine optimierte Version, die auf Laptops und anderen ressourcenbegrenzten Umgebungen ausgeführt werden kann. Diese Edition wird kostenlos zur Verfügung gestellt und kann In-Memory-Datenbanken mit bis zu 32 GB verwalten.
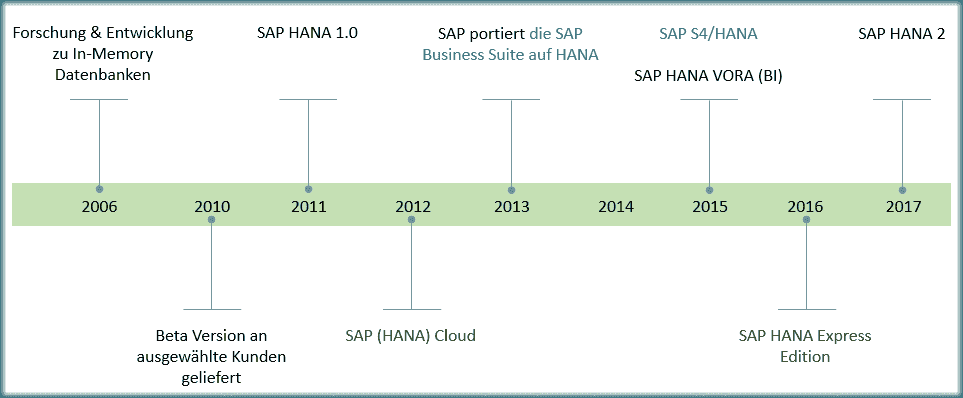
Übersicht der verschiedenen Entwicklungsstadien der SAP HANA Datenbank.
Gleichzeitig verabschiedete sich SAP von seiner klassischen Release-Strategie und verwendet sogenannte Support Package Stacks (SPS) die alle 6 Monate veröffentlicht werden und Aktualisierungen (Fehlerbehebungen und neue Funktionalitäten) enthalten. Der Vorteil ist, das diese SPS nicht so mächtig sind wie Releases, die alle paar Jahre erschienen: so ist der Aufwand bei den Kunden Systemen geringer, und das Ausrollen neuer Funktionalitäten erfolgt schneller.
Technologie
Die primäre Funktion von SAP HANA als Datenbank-Server ist das Speichern und Abrufen von Daten. Darüber hinaus führt sie Analysen (prädiktive Analytik, räumliche Datenverarbeitung, Textanalyse, Textsuche, Streaming Analytics, Graphen-orientierte Verarbeitung) und beinhaltet ETL-Fähigkeiten sowie einen Applikationsserver.
In-Memory
Wie bei jeder Datenbank besteht die Hauptfunktion auch bei IMDBs (in-memory database) im Speichern, Abrufen (und Löschen) von Daten. Die zu verarbeitenden Daten werden jedoch im Arbeitsspeicher (RAM) gehalten und nicht auf magnetischen Festplatten oder Flash-Speichern. Dieser bietet wesentlich höhere Zugriffsgeschwindigkeiten als Festplattenlaufwerke und die Algorithmen für den Zugriff sind einfacher. Zudem sind die Zugriffszeiten besser vorhersagbar als die von Festplatten basierten Datenbanken. Inzwischen sind die Preise für RAM (Arbeitsspeicher) dermaßen niedrig, das dies kaum noch als Nachteil anzuführen ist.
Allerdings braucht es geeignete Konzepte, um die Persistenz bei der Datenspeicherung zu sicherzustellen (Stromausfälle, Hardwarefehler, etc.): Schnappschuss-Sicherung, Transaktionsprotokoll, etc.
Spaltenorientierte Datenbank
Spaltenorientierte DBMS (database management system) speichern alle Daten für eine einzelne Spalte am selben Speicherort, anstatt alle Daten für eine einzelne Zeile am selben Speicherort zu speichern (zeilenorientierte Systeme).
Spaltenorientierte Datenbanken sind in Bezug auf lesende Zugriffe, und den typischen Aggregation die für Auswertungen benötigt werden, viel schneller als die klassischen zeilenorientieren Datenbanken sind. Damit eröffnet sich die Möglichkeit einer Echtzeit Auswertung auf Basis des operativen Datenbestands
Hinweis: eine „Tabelle“ besteht immer aus Zeilen und Spalten, und wird von beiden Systemen auch so abgebildet. Der Unterschied zwischen den beiden Datenbank-Systemen liegt in der technischen Implementierung.
Hinzu kommt ein Konzept der "späten Materialisierung" von Daten: die Daten sind in komprimierter Form gespeichert und es werden so viele Joins, Views, Selektionen, Filter und Aggregationen wie möglich durchgeführt bevor die Daten in de-komprimierter Form visualisiert werden.
Ein Nachtteil ist, das spaltenorientierte Datenbanken langsamer beim Einfügen (vieler) neuer Zeilen sind. Dies geschieht in vielen ERP Systemen in der Nacht durch die Batchverarbeitung, wird aber durch die in-Memory Technologie ausglichen.
Hybrid – OLAP / OLTP
Diese Architektur ermöglicht die Durchführung von transaktionalen (OLTP, Online-Transaction-Processing) und analytischen Prozeduren (OLAP, Online Analytical Processing) im selben System.
Dadurch kann die Verarbeitung und Analyse großer Datenmengen (Big Data) nahezu in Echtzeit auf dem produktiven Datenbestand stattfinden.
OLAP steht im Gegensatz zu OLTP, das in der Regel durch viel weniger komplexe Abfragen gekennzeichnet ist, um Transaktionen anstatt Daten zu Zwecken der Berichtserstellung und Business Intelligence (Datawarehouse (DWH)) zu verarbeiten. Während OLAP-Systeme meistens auf das Lesen von großen Datenmengen optimiert sind, muss OLTP alle Arten von Abfragen (Lesen, Einfügen, Änderungen und Löschen) verarbeiten.
Rückblick: Seit die EDV mit Ende der 70iger Jahre in kommerziellen Unternehmen nicht mehr wegzudenken war, hat sich folgendes Paradigma durchgesetzt: Es gab eine Hardware (und Datenbank / Applikationsserver) für die operative Verarbeitung. Und parallel dazu eine zweite, Datawarehouse (DWH) genannt, für Auswertungen. Die DWHs bezogen dabei ihre Daten (redundant!) aus den ERP Systemen, waren aber von ihrer Architektur her auf schnelle Auswertungen optimiert. Der Grund für diese teure, redundante und zeitverzögerte Architektur: es war schlicht nicht möglich, auf dem operativen Datenbestand Auswertungen dieser Art zu fahren, ohne gleichzeitig den operativen Betrieb, durch eine hohe Auslastung der Hardware, zu behindern.
Obwohl zeilenorientierte Systeme traditionell für OLTP bevorzugt wurden, eröffnet die Ablage der gesamten Datenbank im Arbeitsspeicher die Entwicklung von hybriden Systemen, die sowohl für OLAP- als auch für OLTP-Anforderungen geeignet sind, wodurch separate Hard-und Software Architekturen nicht mehr erforderlich sind.
Vorteile / Nachteile
Hier in aller Kürze die wesentlichen Vorteile und Kritik-Punkte
- All diese Features ermöglichen eine Performance-Steigerung um einen Faktor von 50 bis 5.000, abhängig von der konkreten Applikation und insbesondere von der Art und Anzahl der Datenbankzugriffe.
- Für Endanwender und ihre tägliche, dialogbasierte Geschäftsvorfall Bearbeitung, ist hingegen von der Beschleunigung wenig zu spüren, da die Datenmengen die dort verarbeitet werden relativ gering sind.
- Die volle Wucht von HANA entfaltet sich bei den sogenannten Batches, die häufig immer noch über Nacht laufen, und die nun statt 5 Stunden z.B. in 20 Minuten ihre Arbeit verrichten. Dies ist ein immenser Schritt, auch gerade für eine 24/7 Verfügbarkeit.
- Noch größer sind die Vorteile bei Auswertungen aller Art, auch für Big Data Analysen, die häufig nahezu in Echtzeit durchgeführt werden können.
- Die Kosten liegen vor allem in den erhöhten Hardware Anforderungen (insbesondere Arbeitsspeicher). Anderseits spart man sich eine zweite Serverlandschaft für den Betrieb eines Datawarehouse (SAP BW).
Hinzu kommen die Kosten für eine Migration von SAP R/3, die allerdings sobald der Support für SAP R/3 ausläuft, ohnehin anfallen.
In diesem Zusammenhang sei auch noch erwähnt, das seit einigen Jahren ein erbitterter „Plattform“-Krieg (Digitales „Ecosystem“) zwischen SAP, Microsoft, (Oracle) und SalesForce tobt. Ausgelöst durch drei Faktoren:
- zum einen durch die Digitalisierung, die für viele Unternehmen eine möglichst vollständige Automatisierung ihrer Prozesse im Sinne von End-to-End Verarbeitung bedeutet (B2B / B2C).
- Hinzukommt, das viele IT-Abteilungen nach Jahrzehnten endlich begriffen haben, das ein Wildwuchs von Modulen von verschiedenen Herstellern (und evtl. Eigenentwicklungen) extrem schwer (zeitaufwändig, fehleranfällig) zu warten ist.
- Der dritte Punkt ist die Tendenz, IT Applikationen nicht mehr selbst (On-Premise) sondern in der Cloud betreiben zu lassen. Salesforce (1999 gegründet, 25.000 MA in 2018) z.B. ist komplett Cloud-basiert.
 Impressum
Impressum  Datenschutz
Datenschutz